SmartML: A Framework for Automated Selection and Hyperparameter Optimization for Machine Learning Algorithms
A major obstacle for developing machine learning models using big data is the challenging and time consuming process of identifying and training an adequate predictive model. Therefore, machine learning mode building is a highly iterative exploratory process where most scientists work hard to find the best model or algorithm that meets their performance requirement. In practice, there is no one-model-fits-all solutions, thus, there is no single model or algorithm that can handle all data set varieties and changes in data that may occur over time. All machine learning algorithms require user defined inputs to achieve a balance between accuracy and generalizability, this is referred to as hyperparameter optimization. This iterative and explorative nature of the building of distributed process is prohibitively expensive with big datasets. SmartML is a framework that provides automated selection and optimization for building centralized/distributed machine learning models based on the characteristics of the underlying data sets. The framework uses the meta-learning approach where its knowledge base is incrementally recording and updating the performance of the algorithms and parameter setting of the previous run to improve the algorithm selection and tuning for the future runs.
- Salijona Dyrmishi, Radwa Elshawi and Sherif Sakr. A Decision Support Framework for AutoML Systems: A Meta-Learning Approach. Proceedings of the 1st IEEE ICDM Workshop on Autonomous Machine Learning (AML 2019)
- Radwa El Shawi, Mohamed Maher, Sherif Sakr. Automated Machine Learning: State-of-The-Art and Open Challenges. CoRR abs/1906.02287 (2019)
- Mohamed Maher and Sherif Sakr. SmartML: A Meta Learning-Based Framework for Automated Selection and Hyperparameter Tuning for Machine Learning Algorithms. Proceedings of the 22nd International Conference on Extending Database Technology (EDBT'19)
Website: https://bigdata.cs.ut.ee/smartml/
MINARET: A Recommendation Framework for Scientific Reviewers
MINARET is a recommendation framework for scientific reviewers. The framework facilitates the job of journal editors for conducting an efficient and effective scientific review process. The framework exploits the valuable information available on the modern scholarly Websites (e.g., Google Scholar, ACM DL, DBLP, Publons) for identifying candidate reviewers relevant to the topic of the manuscript, filtering them (e.g. excluding those with potential conflict of interest), and ranking them based on several metrics configured by the editor (user). The framework extracts the required information for the recommendation process from the online resources on-the-fly which ensures the output recommendations to be dynamic and based on up-to-date information
- Mohamed Ragab, Mohamed Maher, Ahmed Awad and Sherif Sakr. MINARET: A Recommendation Framework for Scientific Reviewers. Proceedings of the 22nd International Conference on Extending Database Technology (EDBT'19)
Website: https://bigdata.cs.ut.ee/minaret/
Benchmarking of Stream Processing Systems

As the world gets more instrumented and connected, we are witnessing a flood of digital data generated from various hardware (e.g., sensors) or software in the format of flowing streams of data. Real-time processing for such massive amounts of streaming data is a crucial requirement in several application domains including financial markets, surveillance systems, manufacturing, smart cities, and scalable monitoring infrastructure. In the last few years, several big stream processing engines have been introduced to tackle this challenge. In this project, we implemented a framework for benchmarking five popular systems in this domain, namely, Apache Storm, Apache Flink, Apache Spark, Kafka Streams and Hazelcast Jet. The framework is designed to cover the end-to-end benchmarking process and it is quite flexible to be extended for benchmarking additional metrics or to include additional comparison metrics.
-
Elkhan Shahverdi, Ahmed Awad, Sherif Sakr. Big Stream Processing Systems: An Experimental Evaluation. DASC 2019 workshop, held on April 8th within the 35th IEEE International Conference on Data Engineering (ICDE 2019)
DLBench: Benchmarking of Deep Learning Frameworks

Deep learning techniques is gaining an increasing popularity various application domains including image processing, natural language processing, medical diagnosis, speech recognition and computer vision among others. This project evaluates the performance of six deep learning frameworks, namely TensorFlow, Keras, MXNet, PyTorch Theano, Chainer and from different perspectives: speed, accuracy, resource consumption, and GPU utilization. The current evaluation has been done using Convolution Neural Networks (CNN) implementation. However, it can be easily extended to include other deep learning tasks (e.g., RNN, LSTM) and other frameworks as well.
Source Code: Github Repository
FIT Calculator: A Calculator for Predicting Medical Outcomes
FIT Calculator is a machine learning-based calculator for predicting three medical outcomes (Diabetes, Hypertension and All-Cause Mortality) based on patient data.
The Henry Ford Exercise Testing (FIT) Project is a retrospective cohort that includes the information of 69,981 patients who had undergone physician referred treadmill stress testing at Henry Ford Hospital System in Detroit, MI from January 1, 1991- May 28, 2009. Briefly, the study population was limited to patients who are over the age of 18 years of age at the time of stress testing and excluded patients undergoing modified or non-Bruce protocol stress tests. Information regarding the patient's medical history, demographics, medications, cardiovascular disease risk factors were obtained at the time the tests were done by nurses and exercise physiologists, as well as searches through the electronic medical records. All study patients underwent clinically indicated treadmill stress testing utilizing the standard Bruce Protocol. All stress tests were performed in accordance with standard American College of Cardiology/American Heart Association Guidelines.
Machine learning (ML) is a modern data analysis technique with the unique ability to learn and improve its performance without being explicitly programmed and without human instruction. FIT Calculator is based on 3 machine learning models that have been trained with the dataset set of the FIT project to predict 3 medical outcomes: Diabetes Mellitus outcome (ROC=0.92), Hypertension outcome (ROC=0.92) and All-Cause Mortality (ROC=0.93); using the same set of variables.
Website: https://bigdata.cs.ut.ee/fitcalculator/
Data-Driven Interval Analytics (D2IA)
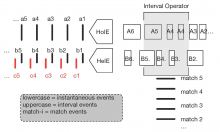
Nowadays, modern Big Stream Processing Solutions (e.g. Spark, Flink) are working towards ultimate frameworks for streaming analytics. In order to achieve this goal, they started to offer extensions of SQL that incorporate stream-oriented primitives such as windowing and Complex Event Processing (CEP). The former enables stateful computation on infinite sequences of data items while the latter focuses on the detection of events pattern. In most of the cases, data items and events are considered instantaneous, i.e., they are single time points in a discrete temporal domain. Nevertheless, a point-based time semantics does not satisfy the requirements of a number of use-cases. For instance, it is not possible to detect the interval during which the temperature increases until the temperature begins to decrease, nor all the relations this interval subsumes. To tackle this challenge, we present D2IA; a set of novel abstract operators to define analytics on user-defined event intervals based on raw events and to efficiently reason about temporal relationships between intervals and/or point events. We realize the implementation of the concepts of D2IA on top of Esper, a centralized stream processing system, and Flink, a distributed stream processing engine for big data.
-
Ahmed Awad, Riccardo Tommasini, Mahmoud Kamel, Emanuele Della Valle, and Sherif Sakr. D2IA: Stream Analytics on User-Defined Event Intervals. The 31st International Conference on Advanced Information Systems Engineering (CAiSE 2019)
Adaptive Watermarks: A Concept Drift-based Approach for Predicting Event-Time Progress in Data Streams

Event-time based stream processing is concerned with analyzing data with respect to its generation time. In most of the cases, data gets delayed during its journey from the source(s) to the stream processing engine. This is known as out-of-order data arrival. Among the different approaches for out-of-order stream processing, low watermarks are proposed to inject special records within data streams, i.e., watermarks. A watermark is a timestamp which indicates that no data with a timestamp older than the watermark should be observed later on. Any element as such is considered a late arrival. Watermark generation is usually periodic and heuristic-based. The limitation of such watermark generation strategy is its rigidness regarding the frequency of data arrival as well as the delay that data may encounter. In this project, we propose an adaptive watermark generation strategy. Our strategy decides adaptively when to generate watermarks and with what timestamp without a priori adjustment. We treat changes in data arrival frequency and changes in delays as concept drifts in stream data mining. We use an Adaptive Window (ADWIN) as our concept drift sensor for the change in the distribution of arrival rate and delay. We have implemented our approach on top of Apache Flink. We compare our approach with periodic watermark generation using two real-life data sets. Our results show that adaptive watermarks achieve a lower average latency by triggering windows earlier and a lower rate of dropped elements by delaying watermarks when out-of-order data is expected.
-
Ahmed Awad, Jonas Traub and Sherif Sakr. Adaptive Watermarks: A Concept Drift-based Approach for Predicting Event-Time Progress in Data Streams. The 22nd International Conference on Extending Database Technology (EDBT'19).