
Founder and Former Head of the Group
Google Scholar
CV
Prof. Sherif Sakr was the Head of Data Systems Group at the Institute of Computer Science, University of Tartu from June 2018 till September 2020. He received his PhD degree in Computer and Information Science from Konstanz University, Germany in 2007. He received his BSc and MSc degrees in Computer Science from the Information Systems department at the Faculty of Computers and Information in Cairo University, Egypt, in 2000 and 2003 respectively. Before joining the University of Tartu, he held appointments in several international organizations including University of New South Wales (Australia), Macquarie University (Australia), Data61/CSIRO (Australia), Microsoft Research (USA), Nokia Bell Labs (Ireland) and King Saud Bin Abdulaziz University for Health Sciences (Saudia Arabia). He also held several visiting appointments at Humboldt-Universitat zu Berlin (Germany), University of Zurich (Switzerland) and Technical Unversity of Dresden (Germany).
Prof. Sakr’s research interest is data and information management in general, particularly in big data processing systems, big data analytics, data science and big data management in cloud computing platforms. Prof. Sakr published more than 150 refereed research publications in international journals and conferences such as: Proceedings of the VLDB Endowment (PVLDB), IEEE Transactions on Parallel and Distributed Systems (IEEE TPDS), IEEE Transactions on Service Computing (IEEE TSC), IEEE Transactions on Big Data (IEEE TBD), ACM Computing Survey (ACM CSUR), Journal of Computer, Systems and Science (JCSS), Information Systems, Cluster Computing, Grid Computing, IEEE Communications Surveys and Tutorials (IEEE COMST), IEEE Software, Scientometrics, VLDB, SIGMOD, ICDE, EDBT, WWW, CIKM, CAiSE, ISWC, BPM, ER, ICWS, ICSOC, IEEE SCC, IEEE Cloud, TPCTC, DASFAA, ICPE and JCDL. One of his papers has been awarded the Outstanding Paper Excellence Award 2009 of Emerald Literati Network. He is also a winner of CAiSE’19 best paper award. Prof. Sakr was a constant reviewer for VLDB J., ACM TODS, ACM CSUR, ACM TWEB, ACM TAAS, IEEE TKDE, IEEE TSC, IEEE TBD, IEEE TCC, IEEE Software, DKE Elsevier, JSS Elsevier, WWW Springer, Distributed and Parallel Databases Springer and many other international conferences and journals.
Prof. Sakr was an associate editor of the cluster computing journal and Transactions on Large-Scale Data and Knowledge-Centered Systems (TLDKS). He was serving as a guest editor for several special issues in various reputable journals including Future Generation Computer Systems and Big Data Research. He is also an editorial board member of many reputable international journals. Prof. Sakr is an ACM Senior Member and an IEEE Senior Member. In 2017, he had been appointed to serve as an ACM Distinguished Speaker and as an IEEE Distinguished Speaker. Prof. Sakr was serving as the Editor-in-Chief of the Springer Encyclopedia of Big Data Technologies. He was also serving as a Co-Chair for the European Big Data Value Association (BDVA) TF6-Data Technology Architectures Group.
Published books:
Publications:
- A. Bonifati, I. Holubova, A. Part-perez, S. Sakr (2020) “Graph Generators: State of the Art and Open Challenges”. Journal of ACM Computing Surveys (CSUR).
- R. Tommasini, S. Sakr, E. Della Valle, H. Jafarpour (2020). Declarative Languages for Big Streaming Data: A database Perspect. Proceedings of the 23rd International Conference on Extending Database Technology (EDBT’20)
- H. Hazem, A. Awad, A. Hassan, S. Sakr (2020). DISGD: A Distributed Shared-nothing Matrix Factorization for Large Scale Online Recommender Systems. Proceedings of the 23rd International Conference on Extending Database Technology (EDBT’20)
- A. Awad, R. Tommasini, M. Kamel, E. Della Valle, and S. Sakr (2019). D2IA: Stream Analytics on User-Defined Event Intervals. Proceedings of The 31st International Conference on Advanced Information Systems Engineering (CAiSE 2019) [PDF] (Best Paper Award).
- A. Awad, J.Traub, S. Sakr (2019). Adaptive Watermarks: A Concept Drift-based Approach for Predicting Event-Time Progress in Data Streams. Proceedings of the 22nd International Conference on Extending Database Technology (EDBT’19) [PDF].
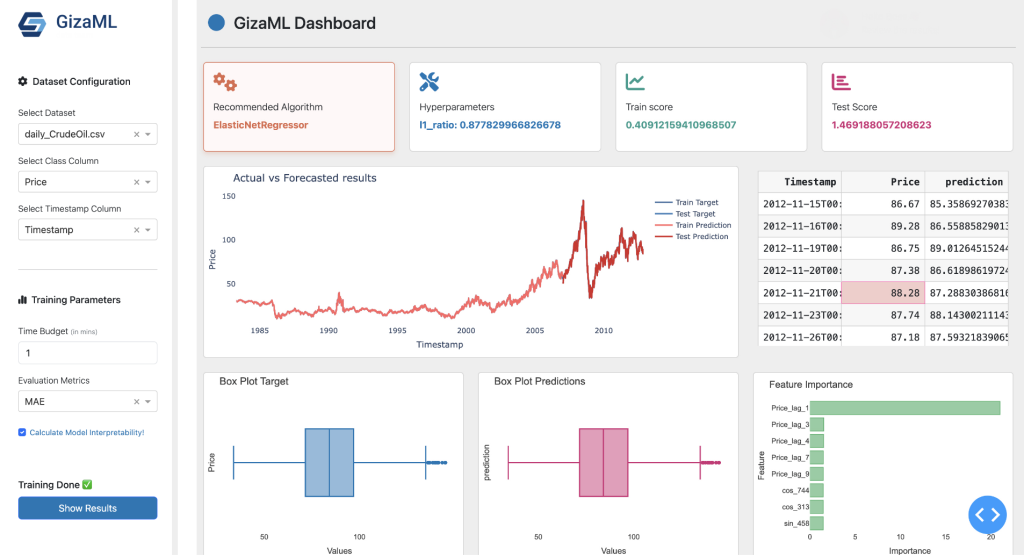
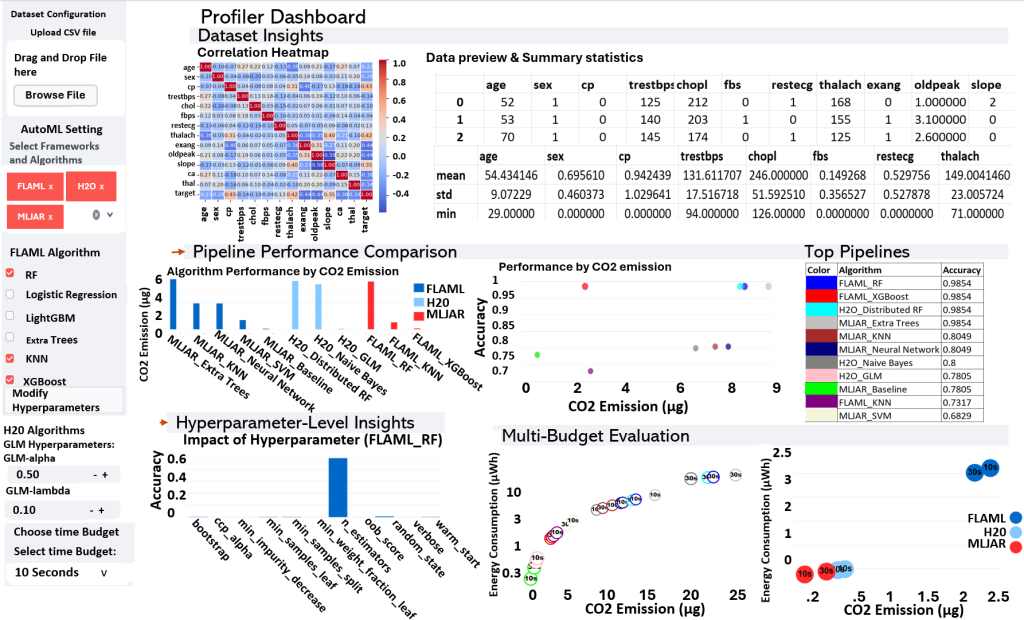
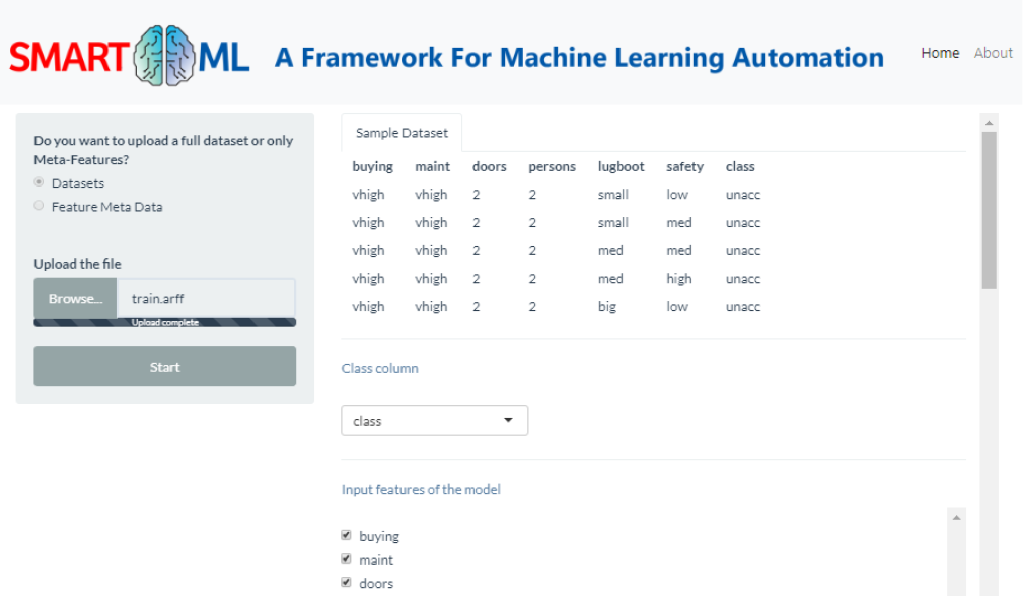
- M. Maher, S. Sakr (2019). SmartML: A Meta Learning-Based Framework for Automated Selection and Hyperparameter Tuning for Machine Learning Algorithms. Proceedings of the 22nd International Conference on Extending Database Technology (EDBT’19) [PDF].
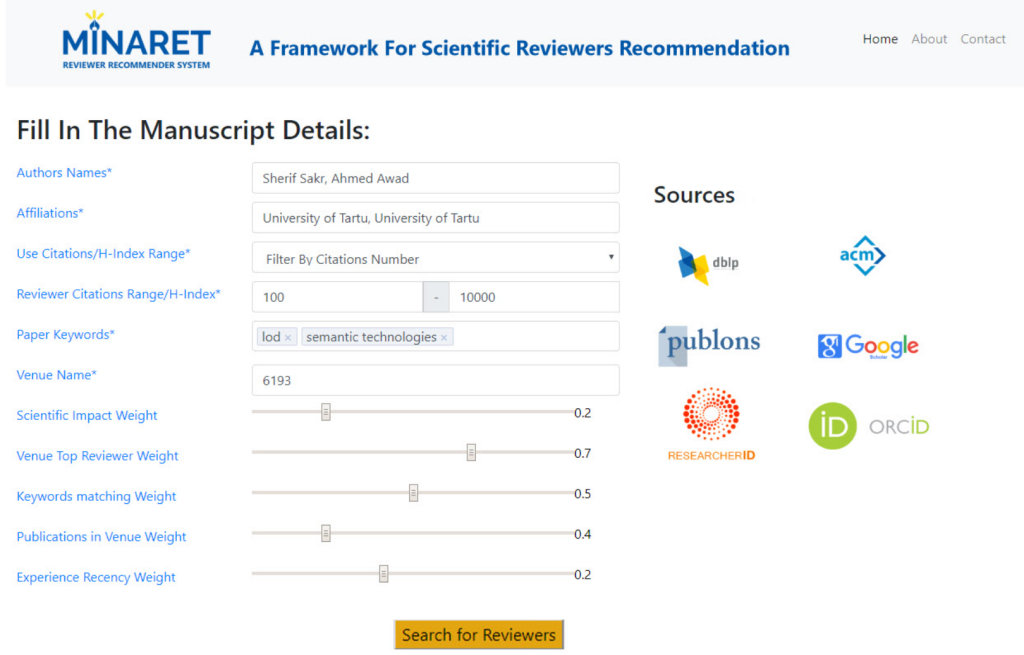
- M. Ragab, M. Maher, A. Awad, S. Sakr (2019). MINARET: A Recommendation Framework for Scientific Reviewers. Proceedings of the 22nd International Conference on Extending Database Technology (EDBT’19) [PDF].
- S. Sakr, Z. Maamer, A. Awad, B. Benatallah, W. Aalst (2018) “Business Process Analytics and Big Data Systems: A Roadmap to Bridge the Gap”. IEEE Access, [PDF].
- M. Wylot, M. Hauswirth, P. Cudré-Mauroux, S. Sakr (2018) “RDF Data Storage and Query Processing Schemes: A Survey”. Journal of ACM Computing Surveys (CSUR), [PDF].
- R. Elshawi, S. Sakr, D. Talia, P. Trunfio (2018), “Big Data Systems Meet Machine Learning Challenges: Towards Big Data Science as a Service”. Journal of Big Data Research, Elsevier. [PDF]
- H. Wu, C. Wang, Y. Fu, S. Sakr, K. Lu, L. Zhu (2018) “A Differentiated Caching Mechanism to Enable Primary Storage Deduplication in Clouds”. IEEE Transactions on Parallel and Distributed Systems (IEEE TPDS), [PDF].
- R. Baca, M. Kratky, I. Holubova, M. Necasky, T. Skopal, M. Svoboda, S. Sakr (2017) “Structural XML Query Processing”. Journal of ACM Computing Surveys (CSUR), [PDF].
- D. Wu, L. Zhu, Q. Liu, S. Sakr, (2017) “HDM: A Composable Framework for Big Data Processing”.IEEE Transactions on Big Data, [PDF].
- D. Wu, S. Sakr, L. Zhu (2017) “Towards Big Data Analytics across Multiple Clusters”. Proceedings of the 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid 2017), Madrid, Spain, [PDF].
- D. Wu, S. Sakr, L. Zhu (2017) “HDM: Optimized Big Data Processing with Data Provenance”. Proceedings of the 20th International Conference on Extending Database Technology (EDBT 2017), Venice, Italy, [PDF].
- S. Sakr (2017), “Big Data Processing Stacks”. IT Professional, IEEE, [PDF].
- S. Sakr, A. Elgammal (2016), “Toward a Comprehensive Data Analytics Framework in Smart Healthcare Networks”. Journal of Big Data Research, Elsevier, Vol 4, [PDF].
- A. Hasan, M. Hammoud, R. Nouri, S. Sakr (2016) “DREAM in Action: A Distributed and Adaptive RDF System on the Cloud”. Proceedings of the 25th International World Wide Web Conference (WWW 2016), Montreal, Canada, [PDF].
- D. Wu, L. Zhu, X. Xu, S. Sakr, D. Sun, Q. Lu (2016), “A Pipeline Framework for Heterogeneous Execution Environment of Big Data Processing”. IEEE Software 33(2), IEEE, [PDF].
- M. Hammoud, D. Abdrabu, R. Nouri, S. Behteshi, S. Sakr (2015) “DREAM: Distributed RDF Engine with Adaptive Query Planner and Minimal Communication”. Proceedings of the 41th International Conference on Very Large Databases (VLDB 2015), Hawai, USA, [PDF].
- L. Zhao, S. Sakr, A. Liu (2015) “A Framework for Consumer-Centric SLA Management of Cloud-Hosted Databases”. IEEE Transactions on Service Computing (IEEE TSC) 8(4), [PDF].
- S. Sakr, S. Elnikety, Y. He (2014) “Hybrid Query Execution Engine For Large Attributed Graphs”.Information Systems Journal, Elsevier Vol. 41, [PDF].
- R. Mutharaju, S. Sakr, A. Sala, P. Hitzler (2013) “D-SPARQ: Scalable SPARQL Query Processing Using Graph Partitioning and MongoDB”. Proceedings of the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, [PDF].
- L. Zhao, S. Sakr, A. Liu (2013) “Consumer-Centric SLA Manager for Cloud-Hosted Databases”. Proceedings of the ACM International Conference on Information and Knowledge Management (CIKM 2013), CA, USA, [PDF]
- S. Sakr (2013) “Cloud-Hosted Databases: Technologies, Challenges and Opportunities”. Cluster Computing Journal, 17(2), Springer, [PDF]
- S. Sakr, A. Liu, A. Fayoumi (2013) “The Family of MapReduce and Large Scale Data Processing Systems”. Journal of ACM Computing Surveys (ACM CSUR) 46(1), [PDF]
- S. Sakr, A. Liu, D. Batista, M. Alomari (2011) “A Survey of Large Scale Data Management Approaches in Cloud Environments”. journal of IEEE Communications Surveys and Tutorials (IEEE COMST) 13(3): 311 – 336, [PDF]












































 Bachelor graduate
Bachelor graduate Bachelor graduate
Bachelor graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s Graduate
Master’s Graduate Master’s graduate
Master’s graduate PhD Graduate
PhD Graduate PhD Graduate
PhD Graduate PhD Graduate
PhD Graduate
 Master’s Student
Master’s Student PhD Student
PhD Student PhD Student
PhD Student Lecturer of Data Management
Lecturer of Data Management Lecturer of Data Management
Lecturer of Data Management Visiting Professor
Visiting Professor Visiting Professor
Visiting Professor
